




图像编辑 两个时下最新「图像编辑」工具:图像通过文本对图像进行编辑
 UI设计师
UI设计师新智元报道
编辑:LRS【新智元导读】谷歌的生产力太猛了...文本引导的图像生成模型火了,同时带火的还有用文本提示对图像进行修改的模型。
比如已经有了一张照片或者是生成的图片,想要给图片中的猫加个帽子,或者给人物换个姿势、图像换个风格,用文字命令的形式输入到模型中,这个过程就叫基于文本的图像编辑(Text-Based Image Editing)。
本文将为大家介绍两个时下最新的「图像编辑」工具。
第一个是浏览器中在线就能用的Runway,其内置在AI Magic Tools下的「Erase and Replace」功能也是刚刚上线。
网站地址:
第二个则是Google Research最近联合魏茨曼科学研究所发布的新模型Imagic,首次实现了应用于单一真实图像复杂的(非刚性的)语义编辑能力。
论文地址:
相比以往的方法限于特定的编辑类型(如物体叠加、风格转移)、仅适用于合成图像、或者需要一个物体的多张输入图像,Imagic可以改变图像中一个或多个物体的姿势和构成,同时保留其原始特征,比如让一只站立的狗坐下、跳起来,让鸟张开翅膀等等。
Stable Diffusion提供的重渲染功能每次编辑都会改变图像中其他的重要元素,所以老手们不得不再使用Photoshop修复丢失元素,而Imagic的处理结果更好(显然不利于Photoshop的推广)。
顺带一提,就在Imagic发布的6个小时后,就被自家兄弟砸了场子。
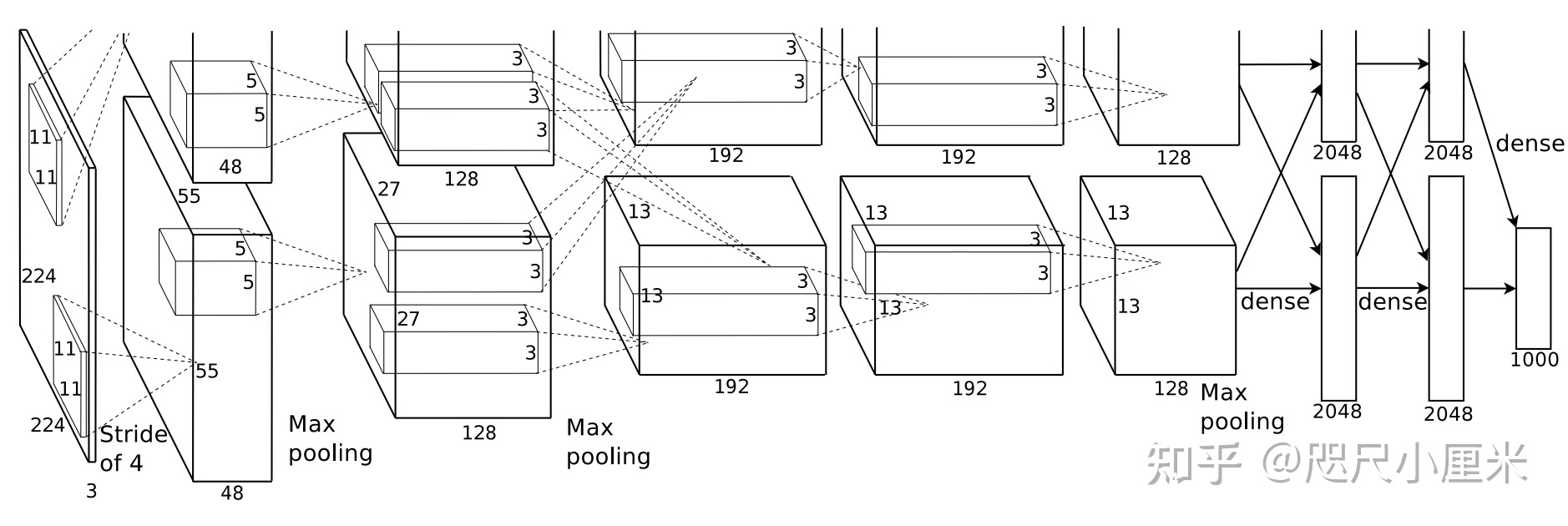
左为Imagic,右为UniTune
Google Research的第二篇论文中提出的模型UniTune同样是在单张图像通过文本对图像进行编辑。
论文地址:
UniTune方法的核心是,通过正确的参数选择,可以在单个图像上对大型文本到图像的扩散模型(文中使用Imagen)进行微调,促使模型保持对输入图像的保真度,同时允许用户进行转换操作。
开箱即用的Runway
Runway中的「Erase and Replace」功能专门处理静止图像图像编辑,尽管 官方在文本到视频编辑解决方案中预览了类似的功能,但该解决方案还没有正式上线。
虽然Runway没有公布该功能背后的技术细节,不过从渲染速度来看,引擎肯定用的是扩散模型,比如Stable Diffusion(或者,不太可能是获得许可的DALL-E 2)Runway系统也有一些类似DALL-E 2的限制,输入的图片或文本触发过滤器机制将会收到一个警告,在发生进一步违规时可能暂停帐户,基本上和OpenAI对DALL-E 2的现行政策一样。
Runway ML是Stable Diffusion的投资方和研究合作伙伴,内部使用的可能是训练过专用模型,其性能优于当前开源的1.4版本,因为就Runway的修改结果来看,编辑后的图像不存在Stable Diffusion中常见的粗糙边缘。
和Imagic一样,Erase and Replace功能是「面向物体的」,用户无法擦除图片中的「empty」部分,然后用文本提示的结果来修改空白部分。如果强行这样做,系统会简单地沿着蒙版的视线追踪最近的明显物体(比如墙或电视) ,然后在找到的物体上应用目标转换效果。
Runway目前是否针对受版权保护的图像在后端渲染引擎中进行优化仍然没有定论,不过从唐老鸭的图画和一些少儿不宜的壁画来看,目前后端检查不是特别严格。
想实现这个功能也可以复杂一点,首先把图像输入到基于某些派生版本的CLIP模型,通过物体识别和语义分割将整张图像分割多个离散的部分,但这些操作产生的结果肯定不如Stable Diffusion的效果好。
Imagic
Imagic主要解决的问题就是物体识别模糊,论文中提供了大量的编辑实例,可以在不影响图像其余部分的同时,成功修改图像。
Imagic模型采用了三阶段的架构。
1. 优化文本嵌入
获取目标文本的词向量后,固定扩散生成模型的参数,将目标词向量通过降噪扩散模型目标进行优化图像编辑,使得文本向量和输入图像的嵌入之间尽可能接近。
重复几个step之后,获得优化后的文本嵌入,使得后续在嵌入空间中的线性插值有意义。
2. 微调扩散模型以更好地匹配给定图像
当把优化嵌入输入到生成扩散的过程中后,并不能精确地导向输入图像,所以还需要再次优化模型的参数。
3. 生成修改后的图像
因为生成扩散模型的训练就是完全对输入图像进行重新创建,而优化后的向量已经是目标图像了,所以想实现编辑操作,只需要在「目标嵌入」和「优化嵌入」之间插值即可。
整个框架和Google之前发布的Imagen类似,研究人员表示,该系统的设计原则广泛适用于潜扩散模型(latent diffusion models)。
Imagen 使用三层架构,包括一个以64x64px 分辨率运行的生成扩散模型;一个超分辨率模型,将输出提升到256x256px;以及一个额外的超分辨率模型,将输出一直提升到1024 × 1024分辨率。
Imagic在训练过程的最初阶段进行干预,用Adam优化器以0.0001的静态学习速率在64px阶段对输入文本的词嵌入进行优化。
然后在Imagen的基础模型上进行微调,对每个输入图像执行1500步修正嵌入空间。
同时,在条件图像上并行优化从64px到256px的第二层,研究人员指出,对最后的256px到1024px图层进行类似的优化对最终的结果「几乎没有影响」,因此在实验中没有增加。
最后,在双TPUv4芯片上对每个图像的优化过程大约需要8分钟。
与谷歌的DreamBooth类似的微调过程一样,由此产生的嵌入可以额外用于强化样式化,以及包含从支持 Imagen 的更广泛的底层数据库中提取信息对相片进行编辑。
研究人员将Imagic与之前的模型进行了比较,包括2021年斯坦福大学和卡内基梅隆大学合作的基于GAN的方法 SDEdit,和2022年4月魏茨曼科学研究所和 NVIDIA 合作的 Text2Live。
很明显,Imagic完胜,尤其是第三个,人物的姿势发生较大的转变,从放松下垂变成抱住胳膊,SDEdit和Text2Live基本没什么反应。
就目前而言,Imagic是一个更适合做成API的产品,不过Google Research对这种可能用于伪造的技术通常很谨慎,不会轻易开源。
参考资料:

转载原创文章请注明,转载自设计培训_平面设计_品牌设计_美工学习_视觉设计_小白UI设计师,原文地址:http://www.zfbbb.com/?id=14249
